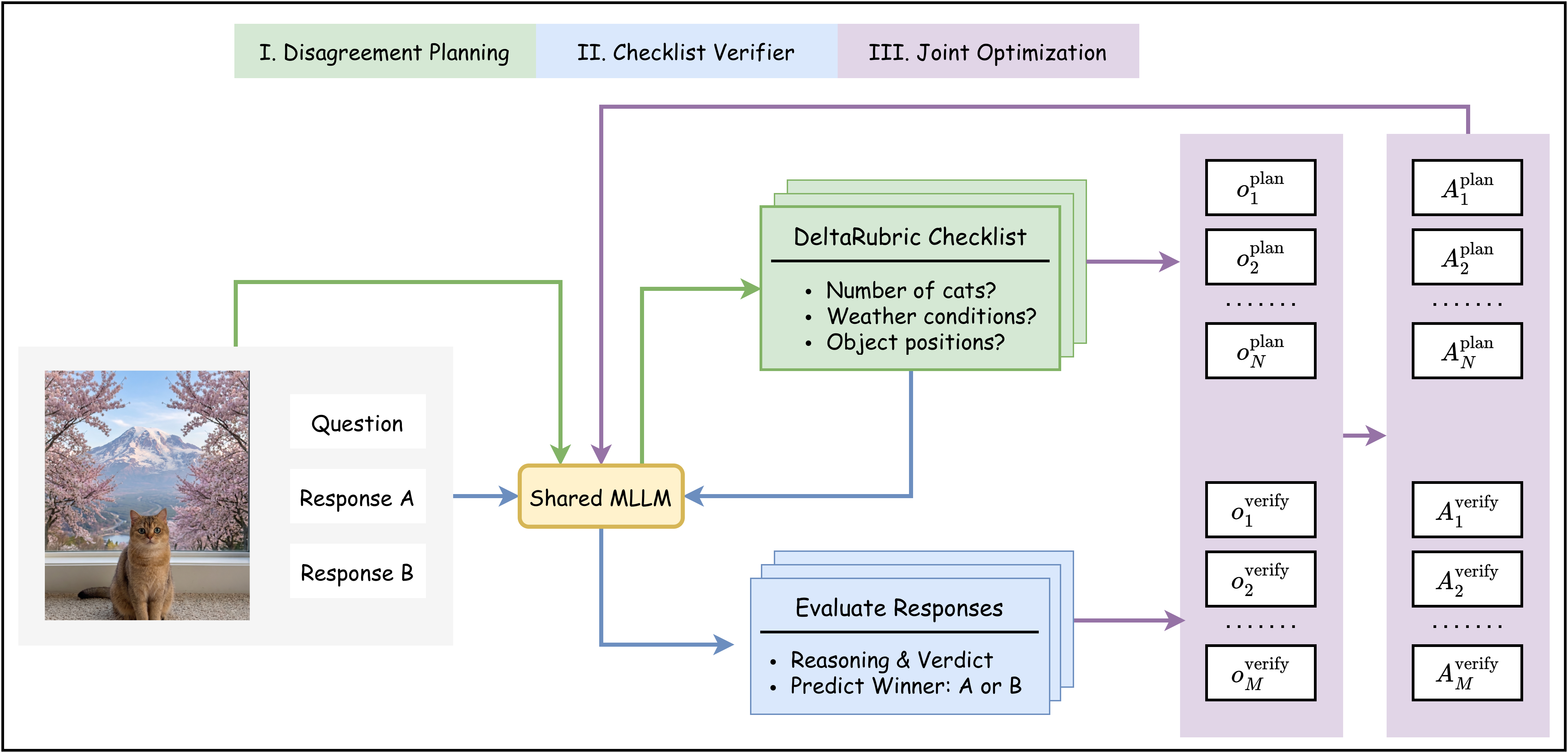
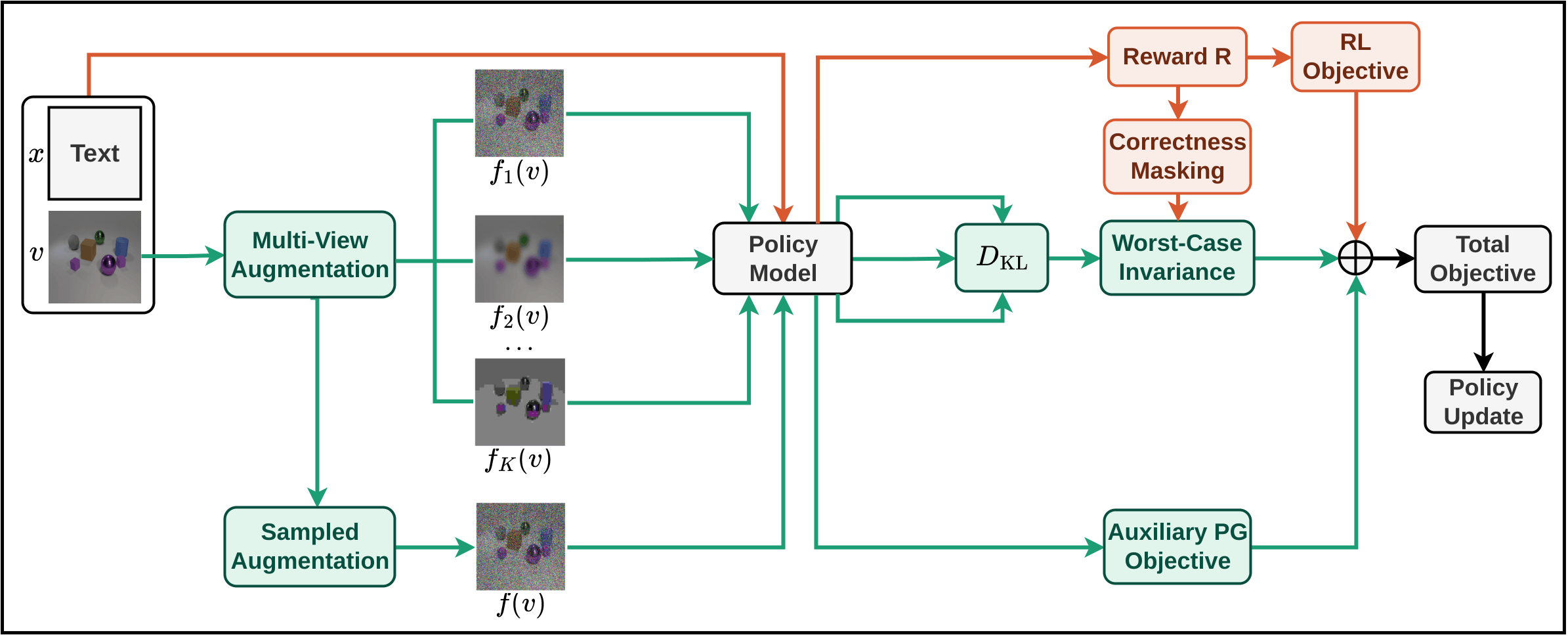
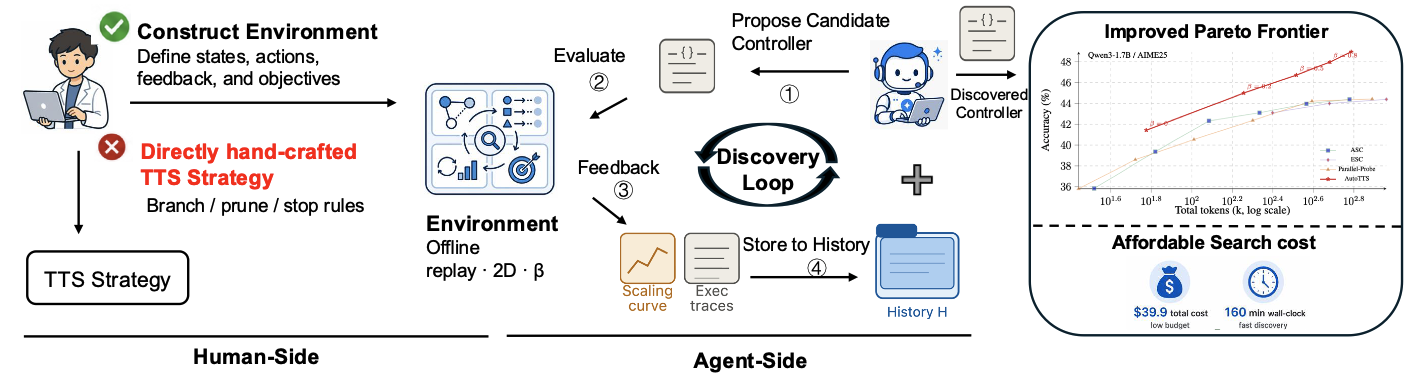
- May 2026: Three new papers out. One on multimodal reward modeling with self-generated, self-evolving rubrics (DeltaRubric). One on mulitmodal reasoning robustness (ROMA). One on automated test-time scaling (AutoTTS).
- Apr 2026: One paper accepted to ICML 2026. One paper accepted to ACL Findings 2026.
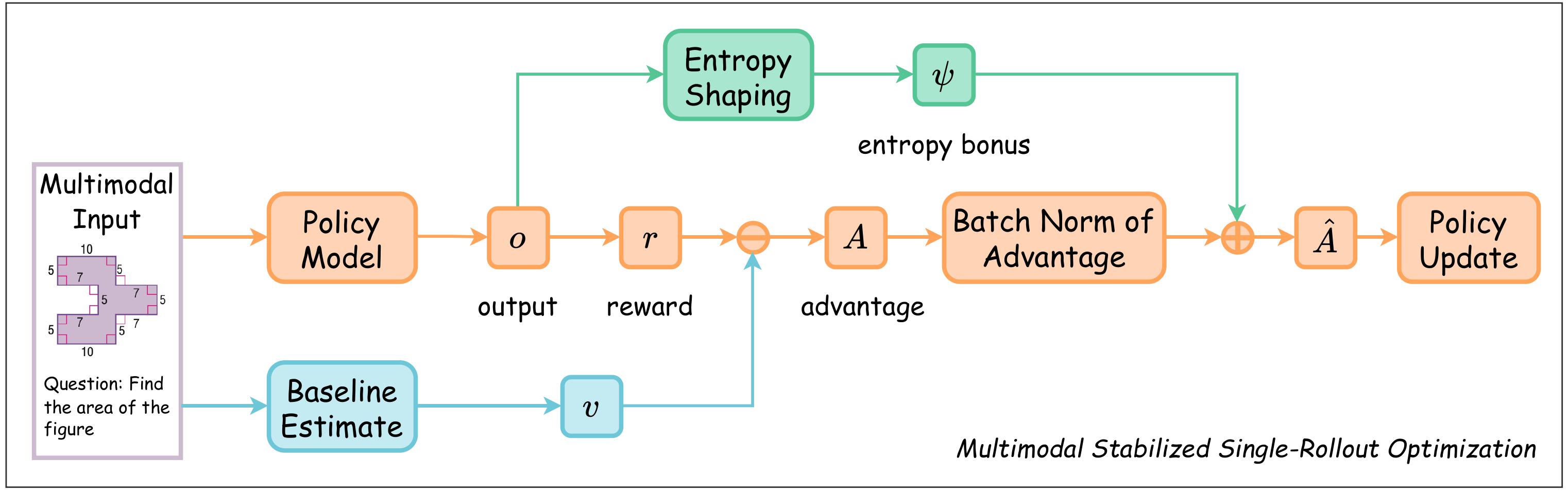
- Feb 2026: MSSR (Multimodal Stabilized Single-Rollout) accepted to CVPR 2026.
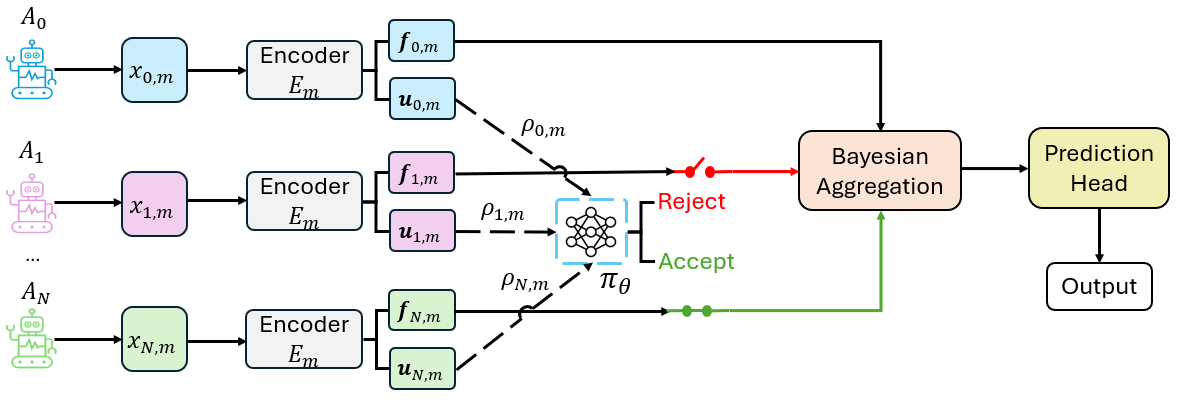
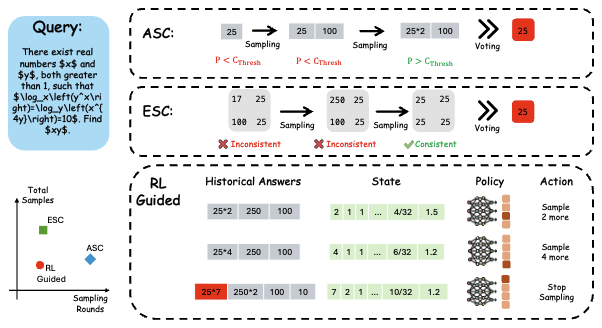
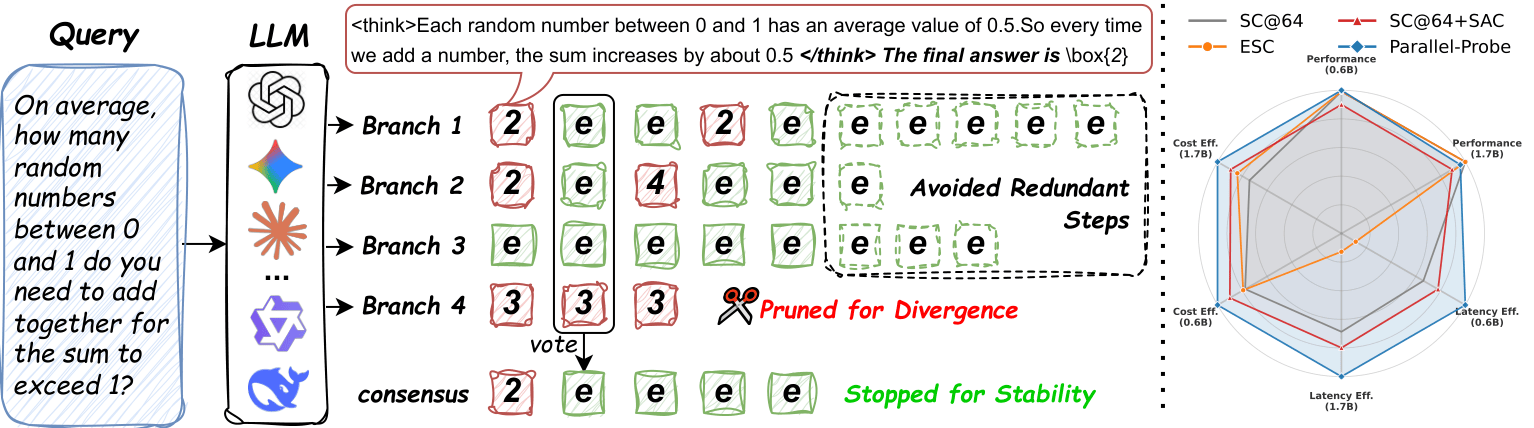
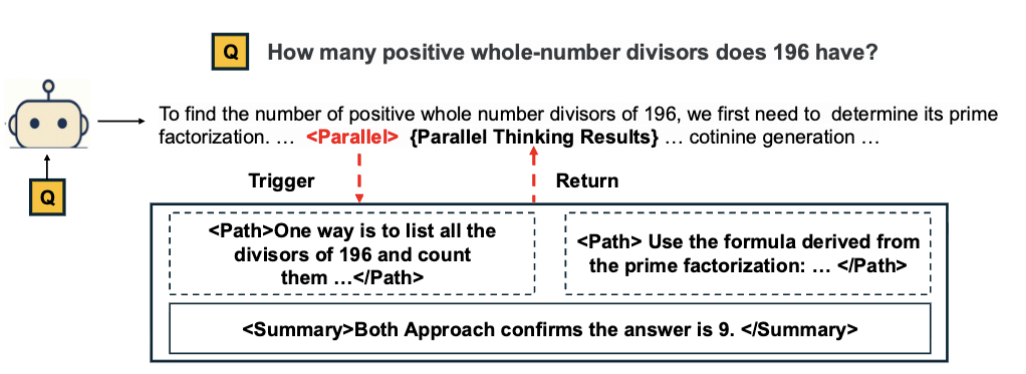
- Feb 2026: Three new papers out. A2MAML for multi-agent multimodal systems, Parallel-Probe for efficient parallel-thinking, VPPO for LLM reasoning with PRM.
- Jan 2026: Four papers accepted to ICLR 2026. Congratulations to all coauthors!
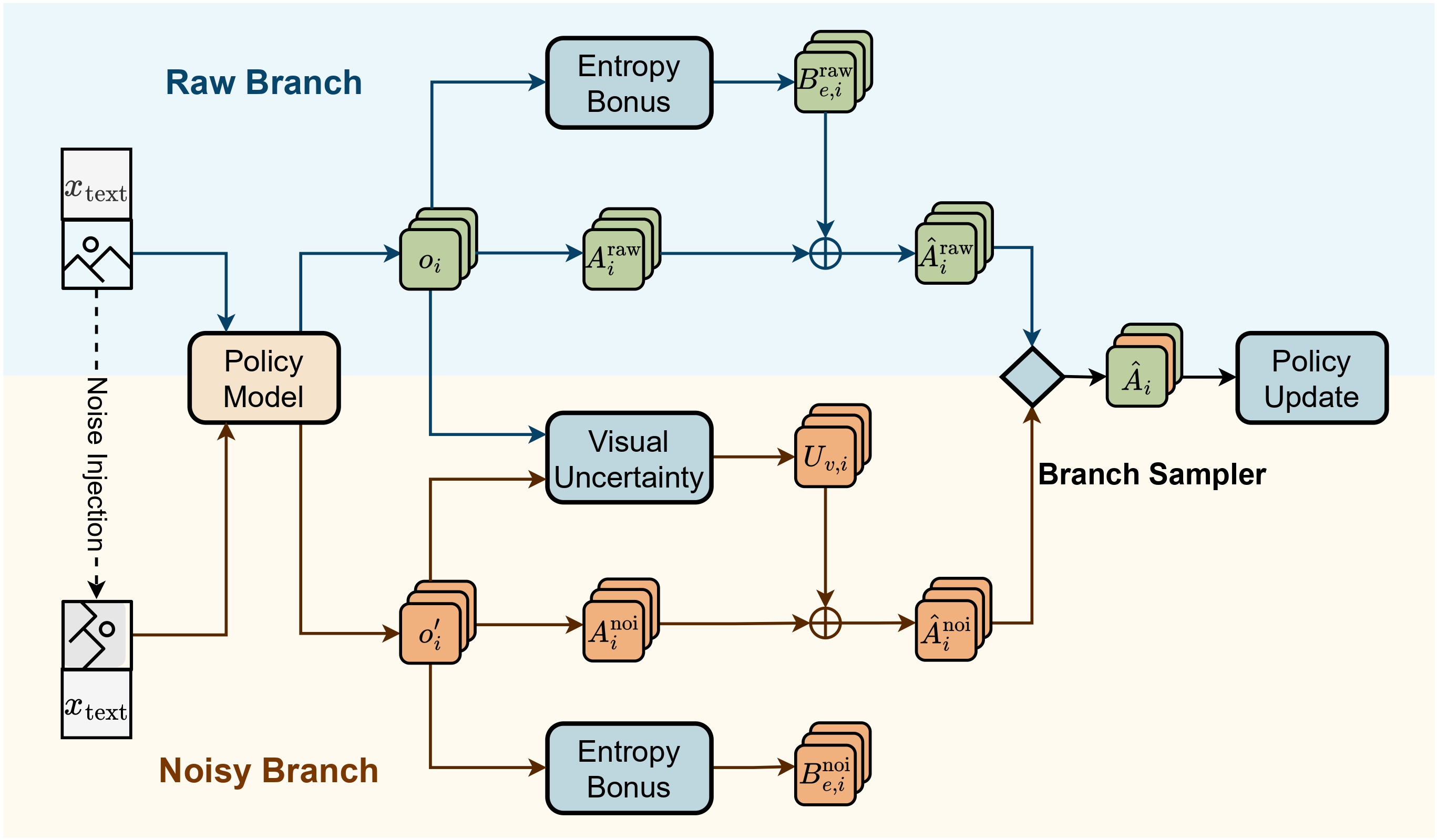
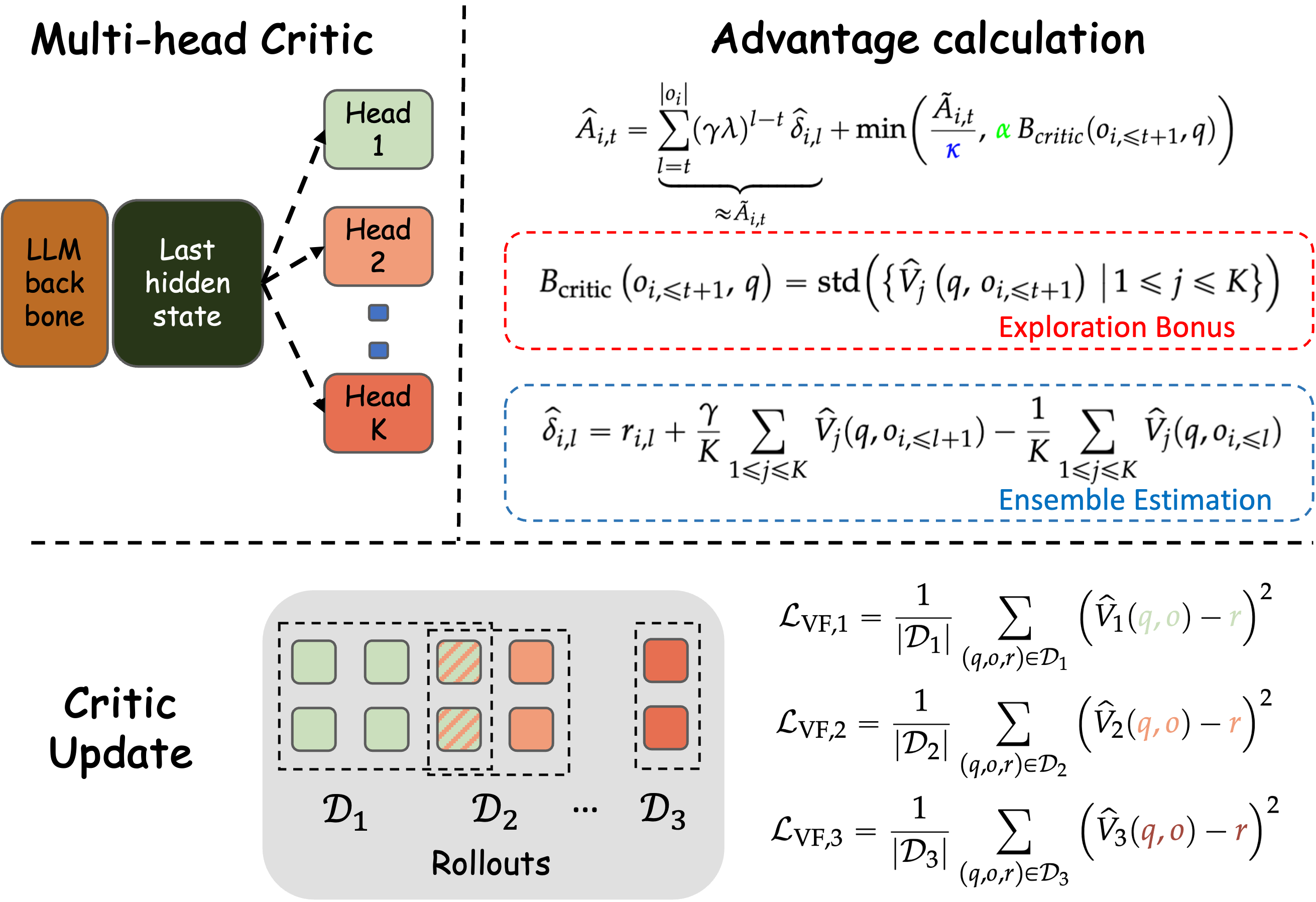
- Jan 2026: Our paper DUPL (Dual-Uncertainty Guided Policy Learning) for multimodal LLM reasoning is out.
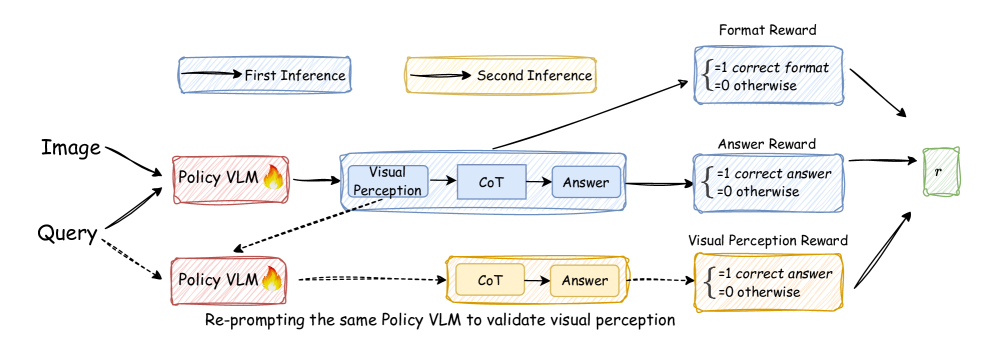
- Dec 2025: Our paper MSSR (Multimodal Stabilized Single-Rollout) for multimodal LLM reasoning is out.
- Sep 2025: Three papers on (multimodal) LLMs reasoning are out. Vision-SR1 for VLM reasoning, Parallel-R1 for parallel thinking with RL, CDE (Curiosity-Driven Exploration) for LLM reasoning.
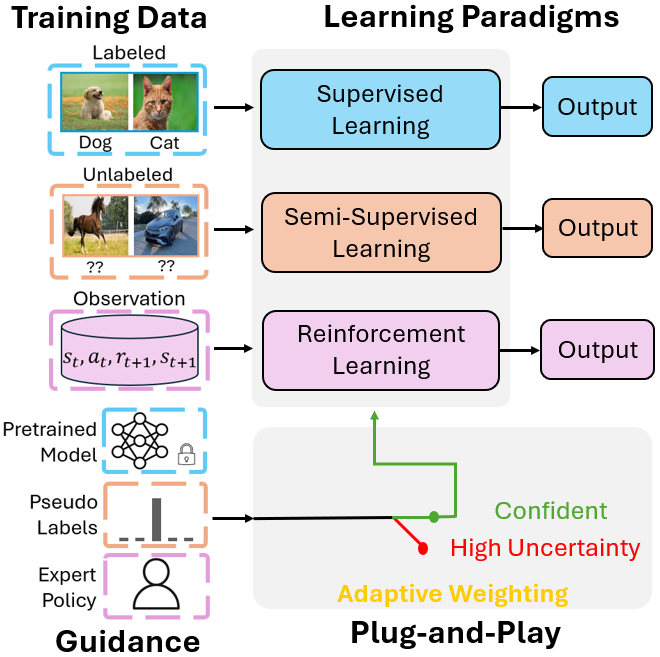
- Sep 2025: One paper on learning under uncertainty (AdaConG) is out.
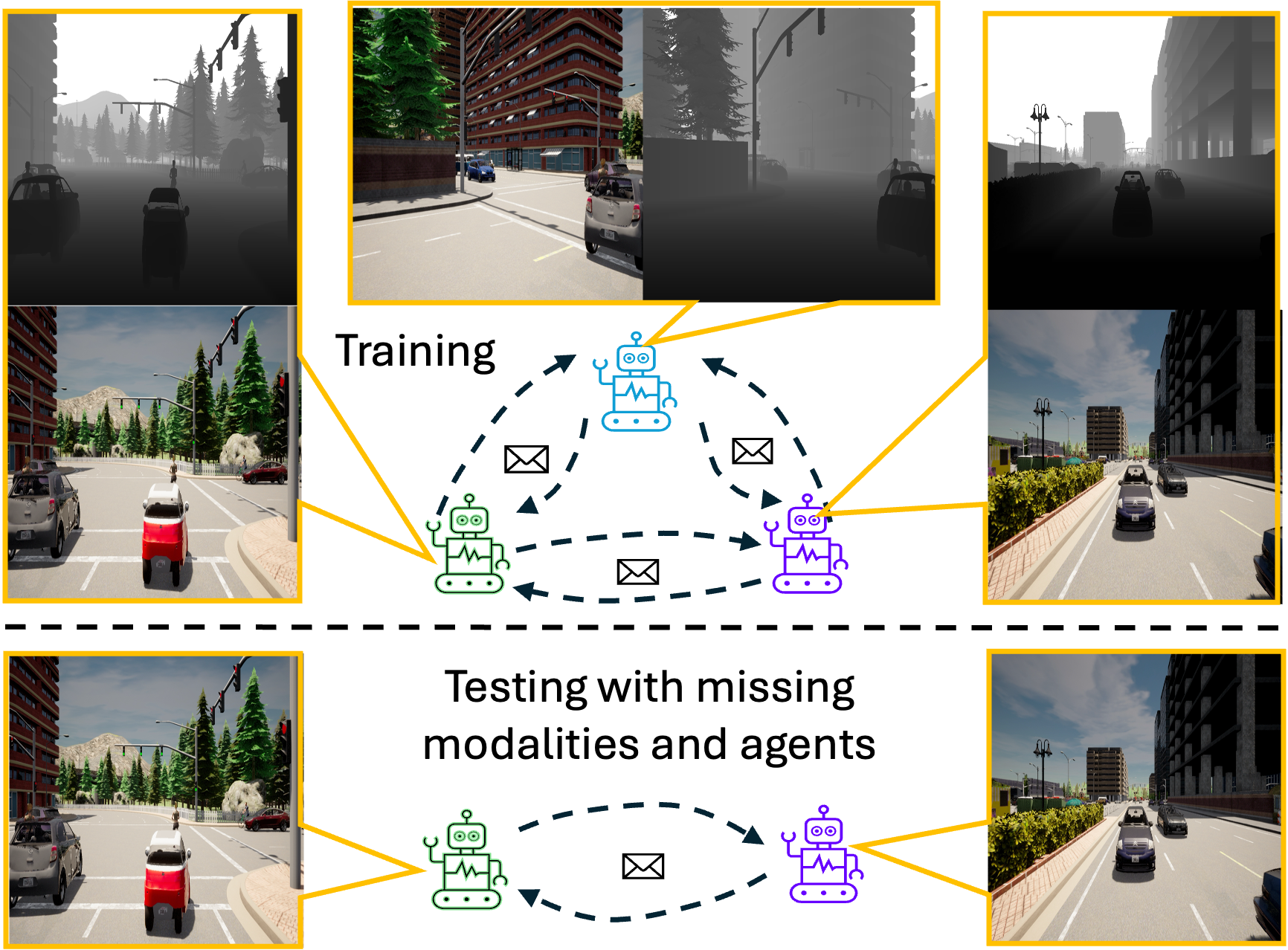
- Sep 2025: One paper on multimodal multi-agent systems (CAML) accepted to NeurIPS 2025.
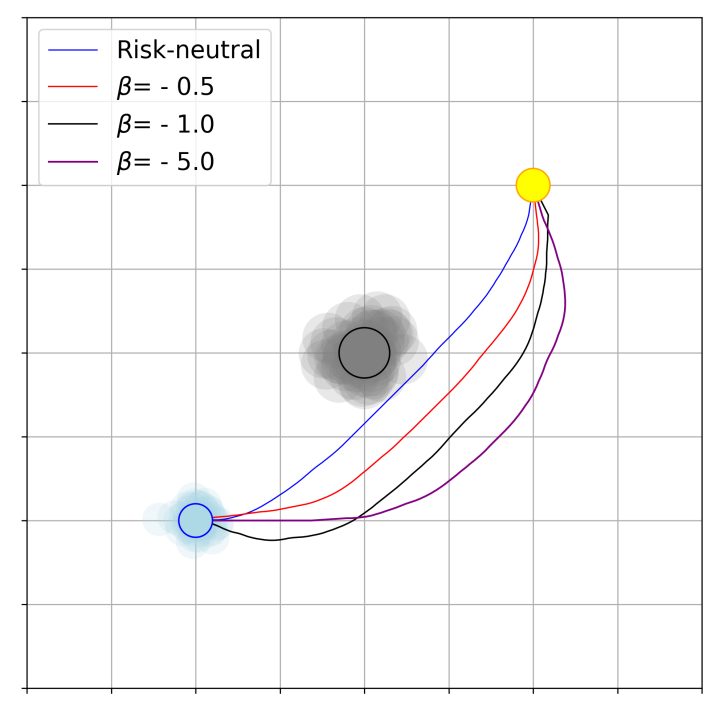
- Aug 2025: One paper on risk-sensitive policy gradient is out.
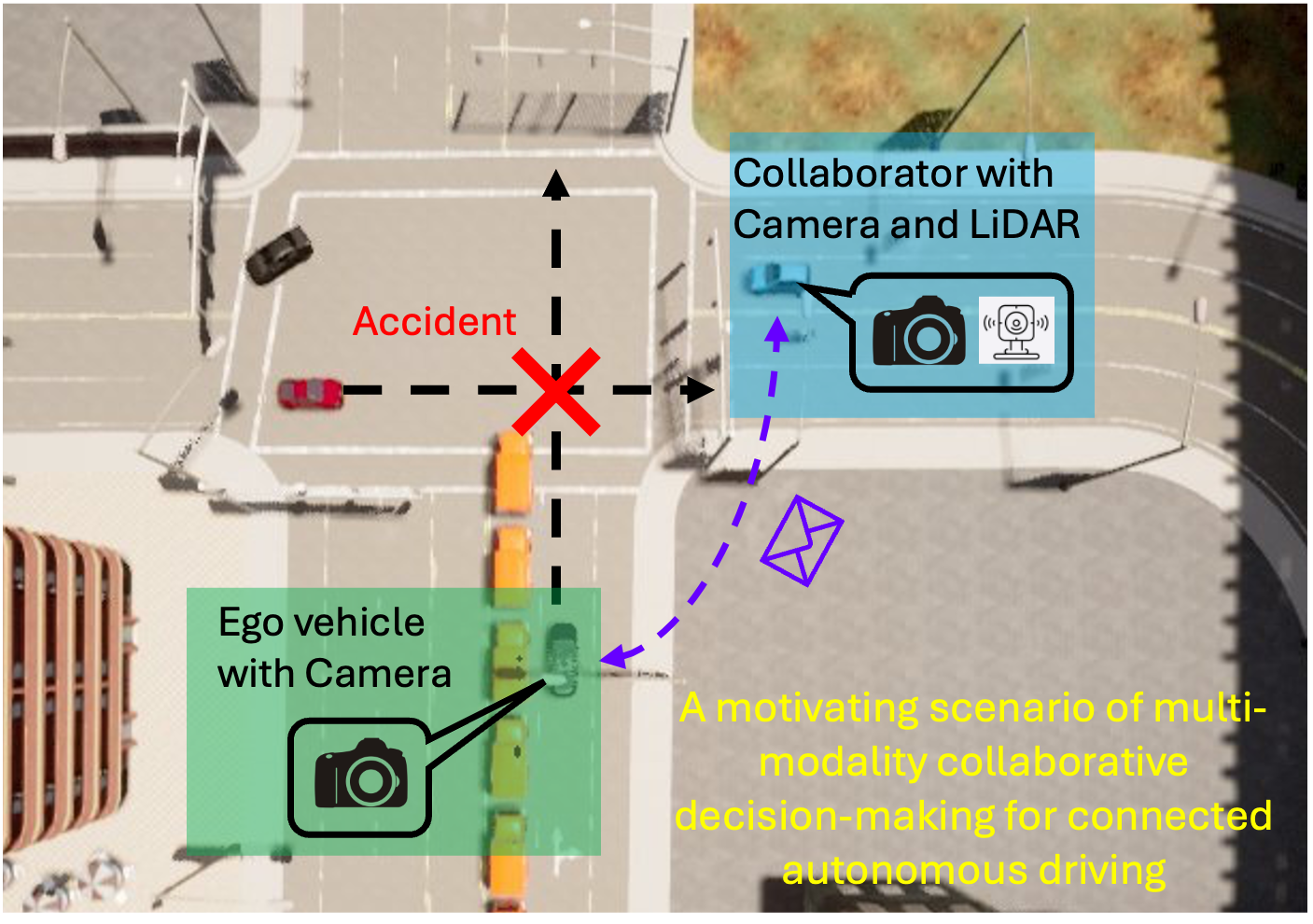
- Jun 2025: One paper on multimodal collaborative decision-making (MMCD) accepted to IROS 2025.
- May 2025: Start my internship at Tencent AI Lab, Bellevue, WA.
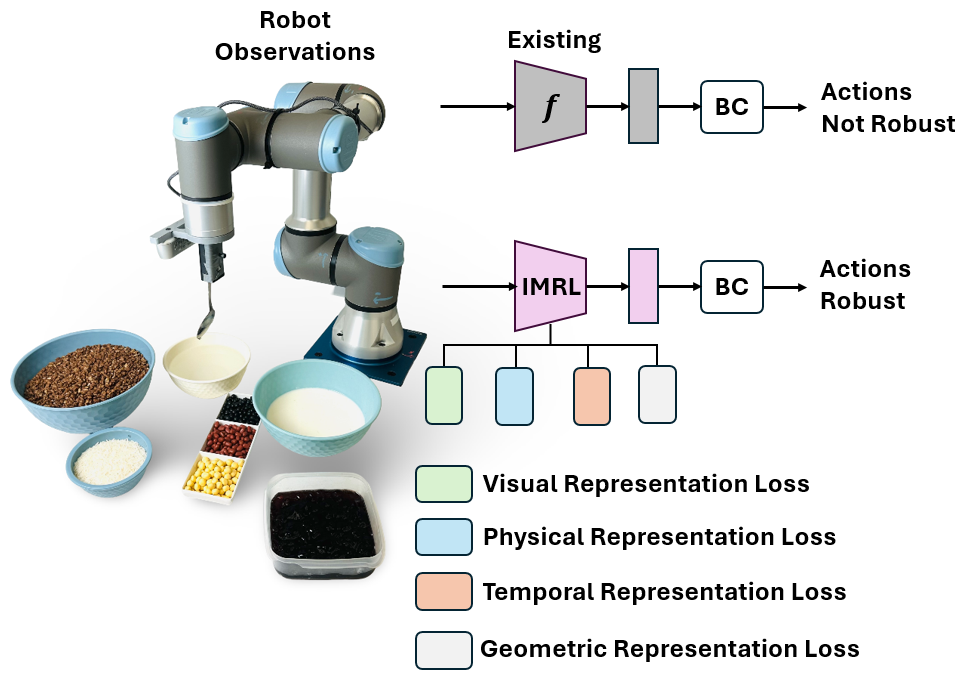
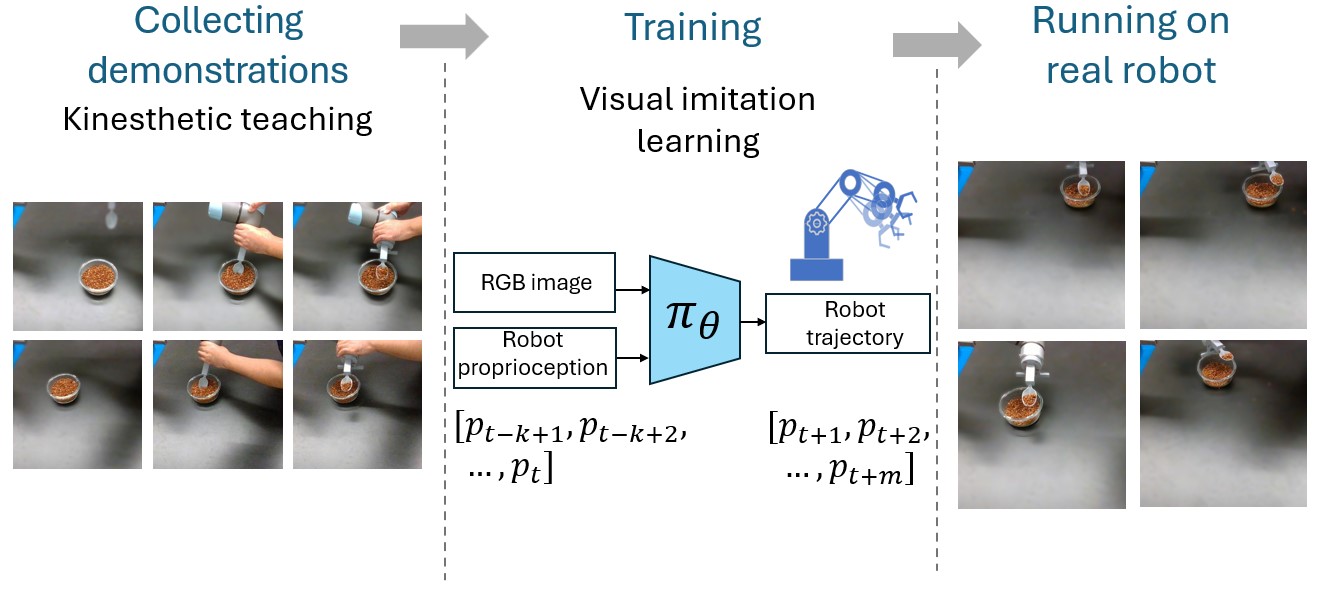
- Jan 2025: One paper on robust imitation learning for robotic manipulation (IMRL) accepted to ICRA 2025.
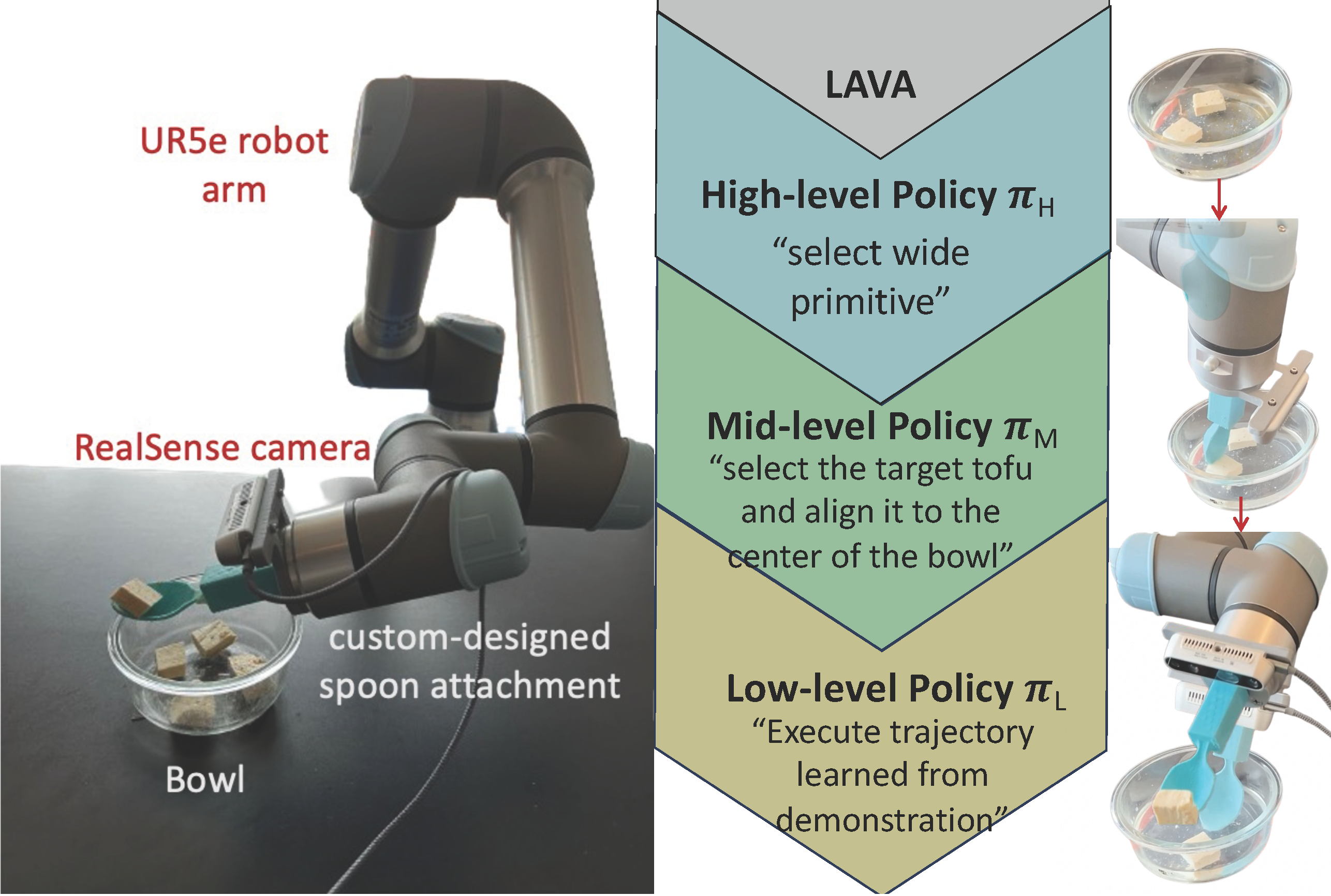
- Jun 2024: One paper on visual action learning for robotic manipulation (LAVA) accepted to IROS 2024.
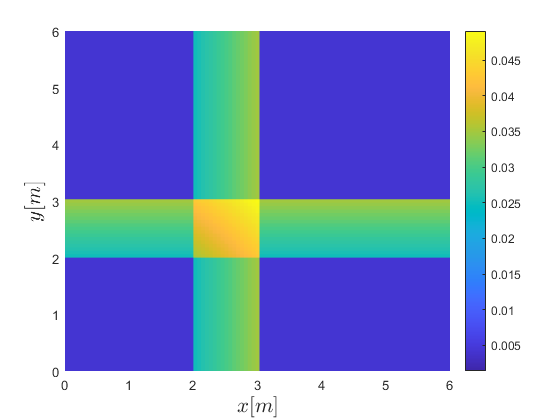
- Jun 2023: One paper on distributionally robust optimal control (D3ROC) accepted to IROS 2023.
- May 2023: Start my internship at Apple, Cupertino, CA.

Hello, I'm Rui Liu
I am a Ph.D. candidate in Computer Science at the University of Maryland, College Park, working with Prof. Pratap Tokekar and Prof. Ming Lin. Previously, I earned my bachelor’s degree from Shanghai Jiao Tong University. I have also interned at Apple, Tencent AI Lab and Tencent Robotics X.
I work on Reinforcement Learning, Multimodal Learning, and Robust Learning etc. My work spans (Multimodal) LLMs Reasoning, Post-training, RL, Agentic AI, and Robotics.